Neo4j can be deployed in multiple ways. Either you can run it as a server in a separate process, just like a classic database, or you can use embedded mode where your application controls the lifecycle of the graph database. Both, embedded and server mode can be used to setup a HA scenario with Neo4j enterprise edition.
In cases where Neo4j is used in embedded mode, there is often a demand for having a maintenance channel to the database, e.g. for fixing wrong data. Nothing simpler than that, there’s an easy way to enable the remote shell together with embedded mode, see a example written in groovy:
[gist id=”8470566″]
The trick is to
have the neo4j-shell-<version>.jar on your classpath and
pass in the config option remote_shell_enabled='true'
With this in place you can use the bin/neo4j-shell from your Neo4j distribution and access your embedded instance.
Back in May this year I’ve attended the Gr8conf in Copenhagen. As always this conference added couple of things to my personal “take-a-look-at-this” list. The most exciting thingy for me was ratpack, a lean toolkit for building web applications on the JVM. Ratpack is powered by Netty and provides an event driven network engine as opposed to classic servlet based containers like Tomcat or Jetty which bind threads to requests. In high load scenarios with a huge number of concurrent requests the thread based model suffers from thread blocking wheres Ratpack is almost non blocking. To get familiar with Ratpack I’ve decided to implement a server component for Neo4j based on Ratpack. The first goal was to have a cypher endpoint, just like the standard Neo4j offers. Secondary goals were some more features:
support for multiple output formats: json, html, csv, message pack
ability to get a list of currently running queries and a button to abort each one individually. This is IMHO a feature lacking in classic Neo4j server. Esp. people getting started with cypher tend to write queries that run very long and there is currently now way to abort them.
For the future I’d like to add some more features:
In ratpack you either write inline handlers in src/ratpack/ratpack.groovy or, for more complex cases, write a handler class derived from AbstractHandler and register that in ratpack.groovy.
Ratpack features Google Guice as well, so we can register e.g. a GraphDatabaseService as injectable component. See Neo4jModule, we’re exposing and configuring a GraphDatabaseService, a Cypher ExecutionEngine, a guard (see below) and a QueryRegistry. Other components can refer to them using the @Inject constructor annotation.
The core piece of code is CypherHandler, it parses the cypher command and parameters out of the request, runs it and renders the result depending on the requested content type.
Terminate Queries
From tech perspective this was the most interesting part to write. Neo4j can be run with a optional guard. Since this feature is not part of the public API it is not officially documented and might therefore be changed without further notice – be warned. To enable the guard feature a config option execution_guard_enabled needs to be set to true. However you can get access to the guard by calling ((GraphDatabaseAPI)graphDb).dependencyResolver.resolveDependency(Guard.class). In neo4j-ratpack the guard is exposed as a guice component so any ratpack handler can just inject it.
Each query is registered with a QueryRegistry. Part of that process is setting up a VetoGuard that throws an exception based on a boolean flag. In case of an exception the query is aborted.
Load Tests
Next step was running some load tests to a standard Neo4j server and neo4j-ratpack in order to compare the performance of the server components. All tests were run on my ThinkPad x230 (i7-3520M, 2.9GHz, 16 GB RAM, Ubuntu 13.04). For simplicity load generation and the server itself were running on the same machine – which is by far not perfect, but a starting point.
The intention of these load tests is not measuring Neo4j itself – it focusses on the server component only.
Using jmeter I’ve run a cypher query
START person=node:person(firstName={firstName})
WITH person
ORDER BY person.lastName LIMIT 10
MATCH (uniCity)<-[:IS_LOCATED_IN]-(uni)<-[studyAt:STUDY_AT]-(person),
(company)<-[worksAt:WORKS_AT]-(person)-[:IS_LOCATED_IN]->(personCity),
(company)-[:IS_LOCATED_IN]->(companyCountry)
RETURN person.firstName, person.lastName, person.birthday, person.creationDate, person.gender, person.browserUsed, person.locationIP, personCity.name, uni.name, studyAt.classYear, uniCity.name, company.name, worksAt.workFrom,companyCountry.name
with different parameters against a graph db consisting of 1.6M nodes, 7M relationships and 7M properties. Kudos to my colleague Alex who helped me setting up the dataset based from the LDBC project he’s involved with.
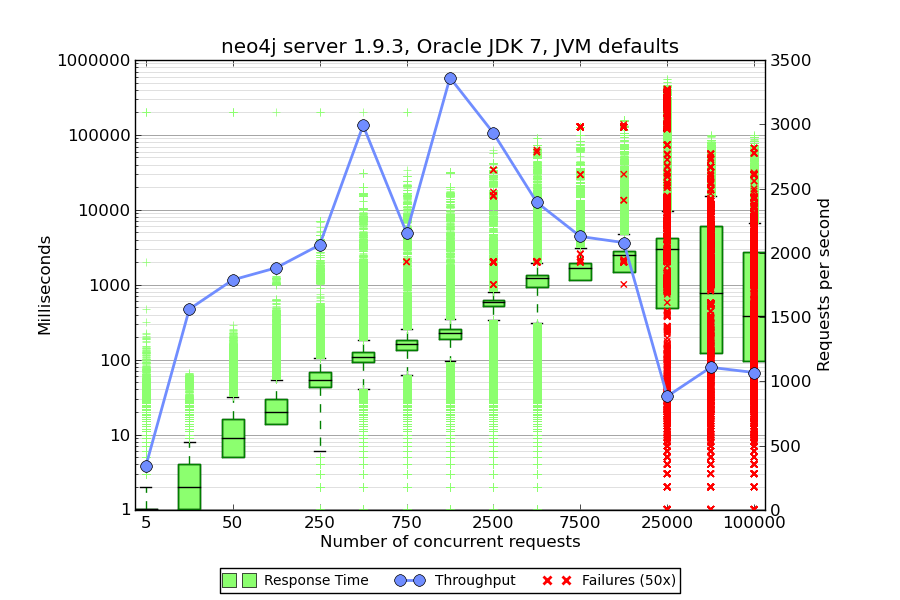
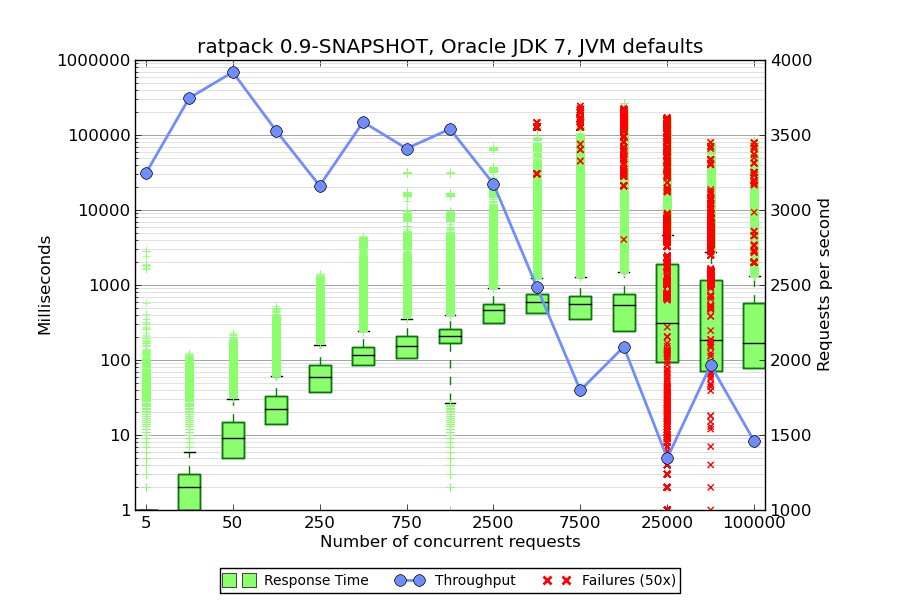
Exactly the same graph.db was used by both Neo4j server and neo4j-ratpack. No specific JVM tuning parameters were set. I’ve run the load test with a increasing number of concurrent threads and focussed on observing throughput and latency. The following diagrams were created using a python matplot script orginating from http://www.metaltoad.com/blog/plotting-your-load-test-jmeter. Please note, the latency is displayed in green on logarithmic axis, throughput is in blue on linear axis (ranges are different for the diagrams).
.
We’re observing a increasing rate of errors when going beyond 25k threads. Since the loadgenerator is colocated with the system to test this seems to be point where jmeter’s own memory and CPU consumption influences the system under test too much – so we’ll disregard the range above 25k.
The most interesting finding is that with ratpack the latency remains nearly constant in the range of [2.5k – 10k] threads whereas the standard neo4j server shows increasing latency. At 2.5k threads ratpack shows fully saturated CPU that’s why throughput decreases. With more or faster CPU we could improve both, latency and throughput. The explanation for the difference observed can be found in the different threading model. Neo4j server uses internally jetty which does blocking IO in opposite to ratpack using Netty. To verify this, I’ve taken threaddumps with yourkit:
threading telemetry of neo4j serverthreading telemetry of neo4j-ratpack
It’s interesting to see that Neo4j server uses 10 worker threads per core (40 in total on my laptop). Most of the time, most of them are in blocked status indicated by the red color. Ratpack on the other side has 8 worker threads being mostly in ‘green’ aka runnable status. So ratpack indeed uses non blocking IO.
Conclusion
For cypher-only use cases with high concurrency requirements using ratpack instead of neo4j server might be an interesting alternative. However be aware, ratpack is bleeding edge, the current version is 0.9-SNAPSHOT.
Groovy has a very convenient to use API for accessing databases over JDBC. My colleagues at Neo Technology brought up a JDBC driver for Cypher. It’s very easy to bring these two together. The only ugly thing here is that you have to use a class called “Sql” to emit Cypher statements.
[gist id=”6094267″]
Dependency management is done by using the @Grab annotations. However there is some tweaking required. Not all required libraries are found on Maven central, so we need to add to repos, one for neo4j and one for restlet. Since we need to register a JDBC driver, the dependencies must be configured on system classloader level.
Update:
Neo4j Cypher JDBC driver also allows the usage of parameterized Cypher which know JDBC users by the term “prepared statement”. This is shows in l. 16. Since JDBC does not support named parameters you have to use numbers for the parameters, starting with “{1}” and provide a list of parameter values.
With this small example you can access your Neo4j server very easily.
In a project I’m involved with there is still a very old Neo4j 1.0 database used. Now this database should be used with an up-to-date version of Neo4j (1.7.2 as of this writing).
Following Neo4j docs, upgrades are done incrementally with every x.y in-between version by starting up and shutting the DB. For upgrading, a config parameter allow_store_upgrade=true must be set.
I’ve found manually downloading each intermediate version too boring and hacked a short groovy script helping with upgrading the datastore, see https://gist.github.com/3011606.
The script must be configured with the right database directory and for the desired target version of Neo4j uncomment the matching @Grab annotation. So when going from 1.0 – 1.8 this script must be called 8 times, each time with the next subsequent @Grab activated.
For those who wonder what the @Grab annotation does: it accesses a maven repository, downloads the dependencies behinde the scene and adds them to the class path.
The upgrade itself is trivial, just fire up an EmbeddedGraphDatabase with allow_store_upgrade=true and shut it down afterwards.
You might know this situation: in a project you start by hacking code that uses i18n properties instead of fixed strings in order to support multiple languages. The normal process in Grails is to use the g:message tag in controllers or gsp templates. Side by side you append the new introduced i18n property with some value in your messsages.properties file.
When support for a new language is requested, all you have to do is translating messages.properties. So far so good – this make i18n really easy.
But: when the project evolves, there’s a good chance that some of your i18n properties in messages.properties gets orphaned. Assume you remove a block of code from a gsp. It happens often that the i18n properties used in this block are not removed from messages*.properties because at some point you are not sure if it is referenced elsewhere. So what would be really useful here would be a list of all referenced i18n properties from your *.groovy/*.gsp files.
Doing so is pretty easy, just add a new gant script to your Grails application’s script folder, let’s name it i18nList.groovy. This script basically contains:
includeTargets << grailsScript("Init")
target(main: "create a list of all i18n properties used in groovy code and gsp templates") {
def properties = []
new File(".").eachFileRecurse {
if (it.file) {
switch (it) {
case ~/.*\.groovy/:
def matcher = it.text =~ /code:\s*["'](.*?)["']/
matcher.each { properties << it[1] }
break
case ~/.*\.gsp/:
def matcher = it.text =~ /code=["'](.*?)["']/
matcher.each { properties << it[1] }
break
}
}
}
println properties.sort().unique().join("\n")
}
setDefaultTarget(main)
(sorry the color coding seems to fail for some Groovy regexes) The script recursivly iterates over all *.groovy and *.gsp files in your project and extract the part after the ‘code’ attribute of the message tag using a regex. The regex result are collected into an array. This array is sorted, unique’d and printed to the console. That’s it.
One word of caution: this gant script ‘works for me’. So depending on your code, you might notice that the used regex are not sufficient or even fail. Feel free to modify them for your needs, even better send back your modifications.
My favorite gadget for the last few months is definitely the Nokia N900. It’s a geeky device with a real Linux OS aboard. In opposite to it’s locked down competitors, the N900 runs Maemo, a platform consisting (mostly) of open source software. So I wonder if it’s possible to use Groovy on that. And yes, it is possible!
Today an important update of the Grails Neo4j plugin has been released. Neo4j is a graph database, it’s main concepts are described in brevity in a previous post. The plugin provides a convenient way to use Neo4j as a persistence layer for Grails domain classes.
The key features / changes of this release are:
domain classes managed by Neo4j can now co-existing with traditional domain classes (aka mapped by Hibernate)
Upgrade to Neo4j 1.0
usage of Grails dependency resolution instead of embedding the jars in /lib directory
added a seperate controller to inspect the Neo4j node space
major refactoring using AST transformation, just like in the couchdb plugin
When Grails binds data e.g. when the controller’s bindData method is called, it instantiates a GrailsDataBinder to take the action. GrailsDataBinder configures itself with some basic ProperyEditors. The neat thing is you can extend that behaviour by adding an arbitrary named PropertyEditorRegistrar implementation to the application context. The PropertyEditorRegistrar registers one or multiple PropertyEditors.
A recent use case was the ability to look up some domain instance by a given key and use this for data binding. Coding a seperate PropertyEditor for each domain class would not really be DRY, so I decided to go the groovy way: a DomainClassLookupPropertyEditor:
public class DomainClassLookupPropertyEditor extends PropertyEditorSupport {
Class domainClass
String property
boolean doAssert = true
String getAsText() {
value."$property"
}
void setAsText(String text) {
value = domainClass."findBy${StringUtils.capitalize(property)}"(text)
assert doAssert && value, "no $domainClass found for $property '$text'"
}
}
The PropertyEditor calls the domain class’ findBy<Property> method to look up the desired instance. The PropertyRegistrar looks like this:
public class MyPropertyEditorRegistrar implements PropertyEditorRegistrar {
public void registerCustomEditors(PropertyEditorRegistry propertyEditorRegistry) {
propertyEditorRegistry.registerCustomEditor(Author, new DomainClassLookupPropertyEditor(domainClass: Author, property: "name"))
propertyEditorRegistry.registerCustomEditor(Book, new DomainClassLookupPropertyEditor(domainClass: Book, property: "isbn"))
}
}
Last, we need to configure that in resources.groovy: