TL;DR
The goal of that blog post is to provide a reasonable haproxy configuration suitable for most neo4j clusters. It covers the Neo4j specific needs (authentication, stickyness, request routing) suitable for typically deployments.
Some words for introduction
When running a Neo4j cluster you typically want to front it with a load balancer. The load balancer itself is not part of Neo4j since a lot of customers already have hardware load balancers in their infrastructure. In case they have not or want some easy-to-go solution for that the recommended tool is haproxy.
In a Neo4j cluster its perfectly possible to run any operation (reads and writes) on any cluster member. However performance-wise it’s a good idea to send write requests directly to the master and send read-only requests to all cluster member or just to the slaves – depending how busy your master is.
What we need to cover
These days most folks interact with Neo4j by sending Cypher commands through the transactional cypher end point. This endpoint uses always a HTTP POST regardless if the Cypher commands are intended to perform read or write operation. This causes some pain for load balancing since we need to distinguish reads from writes.
One approach for this is to use a additional custom HTTTP header on the client side. Assume any request that should perform writes gets a `X-Write:1` header in the request. Then haproxy just needs to check for this header in and acl and associate this acl with the backend containing only the master instance.
Another idea is that the load balancer inspects the request’s payload (aka the Cypher command you’re sending). If that payload contains write clauses like CREATE, MERGE, SET, DELETE, REMOVE or FOREACH it is most likely a write operation to be directed to the master. Luckily haproxy has capbilites to inspect the payload and apply regex matches.
A third approach would be to encapsulate each and every of your use cases into an unmanaged extension and use Cypher, Traversal API or core API inside as an implementation detail. By using the semantics of REST appropriately you use GET for side-effect free reads, PUT, POST and DELETE for writes. These can be used in haproxy’s acl as well very easily.
Another issue we have to deal when setting up the load balancer with is authentication. Since Neo4j 2.2 the database is protected by default with username and password. Of course we can switch that feature off, but if security is a concern it’s wise to have it enabled. In combination with haproxy we need to be aware that haproxy needs to use authentication as well for its status checks to identify who’s available and who’s master.
recommended setup
I’ve spent some time to fiddle out a haproxy config addressing all the points mentioned above. Let’s go through the relevant parts below line by line – for the rest I delegate to the excellent documentation for haproxy. Please note that this config requires a recent version of haproxy:
glory details
defining access control lists
The acl declare conditions to be used later one. We have acls to identify if the incoming request
- has http method of POST, PUT or DELETE (l.16)
- has a specific request header
X-Write:1 - contains one of the magic words in the payload to identify a write: CREATE, MERGE, DELETE, REMOVE, SET
- is targeted at the transactional cypher endpoint
store a variable indicating tx endpoint
We do a nasty trick here: we store a internal variable holding a boolean depending on wether the request is for the tx endpoint. Later on we refer back to that variable. The rationale is that haproxy cannot access acls in other sections of the config file.
decide the backend to be used (aka do we read or write)
The acls defined above decide to which backend a request should be directed. We have one endpoint for the neo4j cluster’s master and another one for a pool of all available neo4j instances (master and slaves). A request is send to master if
- the
X-Write:1header is set, or - the request hits the tx cypher endpoint AND it contains one of the magic words.
- it is a POST, PUT or DELETE.
check status of neo4j instances, eventually with authentication
A backend needs to check which of its member is available. Therefore Neo4j has a REST endpoint exposing the individual instance’s status. In case we use Neo4j authentication the requests to the status endpoint need to be authenticated. Thanks to stackoverflow, I’ve figured out that you can add a Authorization to these requests. As usual, the value for the auth header is a base64 encoded string of “<username>:<password>”. On a unix command line use:
echo "neo4j:123"| base64
In case you’ve disabled authentication in Neo4j, use the commented lines instead.
stickyness for tx endpoint
Using our previously stored variable, we get the value back and use it to declare an acl in this backend. To make sure any request for the same transaction number is sent to the same neo4j instance we create a sticky table to store the transaction ids. You might want to adopt the size of that table (here 1k) to your needs, as well the expire time should be aligned with neo4j’s org.neo4j.server.transaction.timeout setting. It defaults to 60s, so if we expire the sticky table entry after 70s we’re on the safe side. If a http response from the tx endpoint has a Location header we store its 6th word – that is the transaction number – in the sticky table. If we hit the tx endpoint we check if the request path’s 4th word (the transaction id) is found in the sticky table. If so, the request gets send to the same server again, otherwise we use the default policy (round-robin).
define neo4j cluster instances
These lines hold a list of all cluster instances. Be sure to align the maxconn value with the amount of max_server_threads. By default Neo4j uses 10 threads per CPU core. So 32 is a good value for a 4 core box.
haproxy’s stats interface
Haproxy provides a nice status dashbord. In most cases you want to protect that with a password. 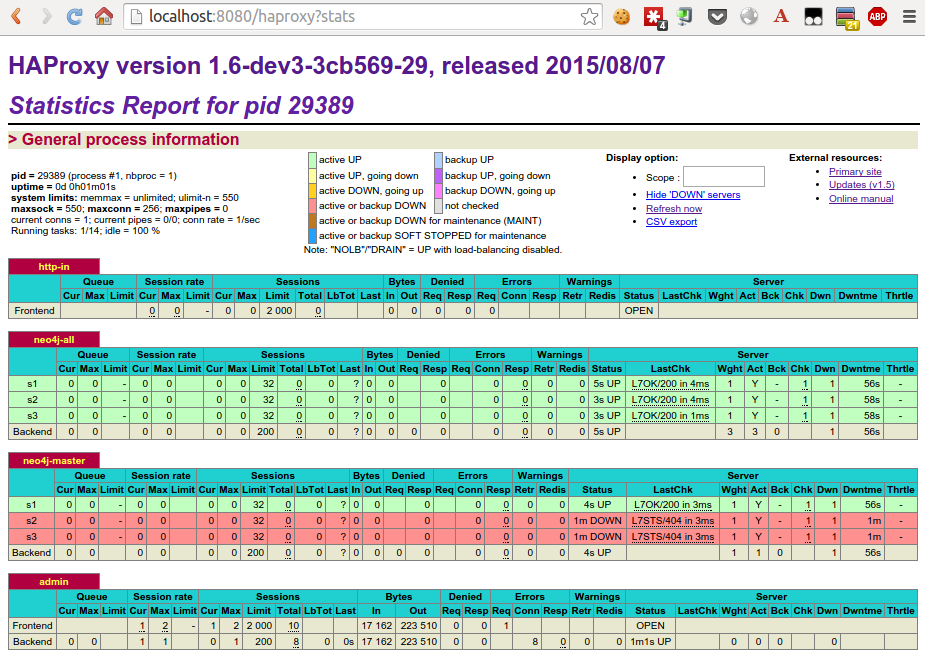
Conclusion
I hope this post could provide you some insights on how to use haproxy in front of a neo4j cluster efficiently. Of course I am aware that my experience and knowledge with haproxy is limited. So I appreciate any feedback to improve the config described here.
Update 2015-10-13
Based on couple of questions I should have more clearly mentioned that the sketched setup requires a haproxy 1.6 which is currently in development.
Update 2015-11-09
Haproxy 1.6 has been released GA on Oct 23rd – so no need to use a in-dev version any more.
Update 2016-10-18
There’s a docker image providing a preconfigured haproxy for neo4j available at https://github.com/UKHomeOffice/docker-neo4j-haproxy. Kudos to Giles.
9 replies on “neo4j and haproxy: some best practices and tricks”
Hi Stefan,
Thanks a lot for the detailed blogpost. I have a “little” concern for the acls defining if the request should go to master. I generally find that only the header is a reliable manner.
1. You can have CREATE, MERGE in the value of a property
2. POST method is used for all Cypher transactional requests, even for READ.
Secondly for “the request hits the tx cypher endpoint AND it contains one of the magic words.” : If you need to handle manually the opening and commiting of transactions, you will issue a POST request to the transactional endpoint without body for eg, so the acl rule will not be matched.
Christophe, thanks for your feedback. I agree a custom header is the most reliable approach.
on 1) I’m aware that my approach might lead to false positive. Since I didn’t want to write a full cypher parser – haproxy 1.6 would allow this using lua code 😉 I think it’s acceptable.
Your second point could in fact lead to situations where a transaction starting with empty (or read only) requests and later on amended a write statement are processed on one of the slaves. This is something you can only avoid by the custom header to indicate a write explicitly.
My fault regarding the non-working log: It works with haproxy 1.6.
Could you please explain what the 6th word of the response’s Location header is (line 33)?
The 6th word of the location header is the transaction number, see https://neo4j.com/docs/developer-manual/current/http-api/#rest-api-begin-a-transaction.
Hi, Im getting started with Neo4j HA clustering and HAproxy.. lets say I have all that configuration done.. how do I connect an app to the cluster, I know is through the HAproxy, but how?.. thanks
You have to point your application to the port configured in the frontend section. In my example it would be `http://:8090`. Amend the URL for the REST endpoint to that base URL, e.g. `http:// :8090/db/data/transaction/commit`.
Hi. I am new to Neo4j and tryting to setup Neo4j cluster. I was able to setup Haproxy and it is running properly. Howerver, when I trying to connect using BOTL protocol, i got below error
Neo4jError: 140735723086656:error:140770FC:SSL routines:SSL23_GET_SERVER_HELLO:unknown protocol:../deps/openssl/openssl/ssl/s23_clnt.c:827
Have you experience any error like this before, if so do you have any resolution to fix it?
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option dontlognull
option redispatch
retries 3
maxconn 2000
timeout connect 30s
timeout client 2h
timeout server 2h
timeout check 5s
frontend neo4j-write
bind *:7687
mode tcp
default_backend neo4j-master
frontend neo4j-read
bind *:7688
mode tcp
default_backend neo4j-slaves
backend neo4j-master
mode tcp
option httpchk HEAD /db/manage/server/ha/master HTTP/1.0
# Server list here
backend neo4j-slaves
mode tcp
balance roundrobin
option httpchk HEAD /db/manage/server/ha/slave HTTP/1.0
# server list here
listen stats
bind *:8000
mode http
stats enable
stats uri /
Have to tried to force your server to use unencrypted bolt?